「ゲノムとアイデンティティ〜ゲノムビジネスの動向」
ゲノムとアイデンティティ、ブロックチェーンとアイデンティティ、そしてゲノム産業はどのようなものか?
ゲノムとアイデンティティ、ブロックチェーンとアイデンティティ、そしてゲノム産業はどのようなものか?
2018.4.23
kizki Report “Genome & Identity”
Kizki レポート 「ゲノムとアイデンティティ〜ゲノムビジネスの動向」
合同会社SARR
(本レポートのダウンロードはこちら)
「ゲノムとアイデンティティ〜ゲノムビジネスの動向」レポート
――――――――――――――――――――――――――――――――――――――
内容
1.ゲノムと個人情報管理に関するリスク
ゲノムは究極の個人情報と言われる。その特性が、他の個人識別可能な情報と異なっているため、取扱についても異なる整理が必要になる。一般には個人識別可能な情報(個人ID、名前、電話番号等)と、個人の特性に関する情報(年齢、性別、購買履歴、移動履歴等)は分離されているが、ゲノムは個人識別可能な情報と特性に関する情報が一体化している。
また、第二の特性としてゲノムに関する科学的知見が発展途上にあることも指摘できる。すなわち、現段階で公開しても問題ない情報が、将来的に何らかの問題を引き起こす可能性がある。
以上のような特性を踏まえて、ゲノムに関連する個人情報保護に関するリスクについて概観する。
1.1では過去に発生したゲノム情報に関する情報管理リスクに関するインシデント事案、1.2~1.5ではゲノム情報を用いた個人情報管理に関して発生しうるリスクについて述べる。1.2~1.6の分類およびリスクについては佐久間(2014)[1]の分類による。1.2~1.5の各ケースでは、ゲノムデータベースの情報を入手し得たとして、個人の特定が可能になるケースを示している。
1.2~1.4では、ゲノムデータと個人の紐づけを行っていない場合でも、データベース情報を入手した者が個人のゲノムを識別しうる可能性があることを示す。
1.5.および1.6では個人ゲノムを何らかの形で利用し、個人アイデンティティとその個人がもつセンシティブな属性(疾病の羅患歴、羅患リスク等)を推定する方法について示す。
1.1 ケース:Personal Genome Project
Personal Genome Projectは、ボランティアからオープンデータとしてゲノムデータを受け取り、医療・科学上の貢献を行うプロジェクトである。このプロジェクトでは個人識別可能なIDを排除した上でゲノムデータを受け取り解析を行っていたが、公開されたゲノムデータから、個人が再特定される事案が発生した。その要因として、以下の事が挙げられた。
・ゲノムデータの提供を行った23andMe社が提供したファイル名に個人が特定可能な名称が付与されていた
・個人がデータを提供する場合に、ファイル名に個人名が付与されていた
・Personal genome Projectが公開したオープンデータにファイル名が含まれていた
以上の事によって、オープンデータプロジェクトにおいて個人とゲノムデータの紐づけが可能になった。現在、Personal Genome Projectにおいては個人の匿名性を保証しない条件でデータの収集・解析を行っている。
Personal Genome Projectでは遺伝学の知識があるものに情報が漏洩した際に以下のような不利益が発生する可能性について明示している。
・父系、その他の血縁関係に関する情報の推定
・雇用、保険、および金融サービスを受ける資格に影響を与える統計的な推定
・被験者および家族の犯罪傾向の推定
・犯罪目的で被験者のDNAを合成し、なんらかの場所等に埋め込む
・治療法の確立していない疾患への羅漢リスクの開示
1.2 ゲノムデータベースと物理接触による体組織取得
匿名化されたゲノムデータベースの内容を取得された場合には、個人識別可能な情報がないため、個人を特定されるおそれはない。しかしながら、体毛等の体組織を入手し、それをシーケンシングすることによって、個人とゲノムデータベースの紐づけを行うケースが想定される。ゲノムデータは本人以外に対して誤って開示されるべきではないため、解析機関は身元不明者からの解析依頼を受けないようにする必要がある。
1.3 ゲノムデータベースと非形質情報の取得
ゲノムデータベース上に個人ゲノムの他に年齢、居住地、生活習慣などの非形質情報と合わせて格納されているケースも想定される。この際に、個人を識別する名前などがなくとも、非形質情報からゲノムデータベース上の個人を特定される可能性がある。例えば、FacebookなどのSNS上で居住地等の非形質データが公開されている事がある。また、これらの情報は医療機関においても業務上収集しているため、医療機関から非形質情報が流出することによって、特定個人のゲノム識別が可能になるリスクが存在する。
すなわち、個人名などのアイデンティティが付与されていないゲノムデータであっても、非形質情報が付与されている場合には、SNS等から再度絞り込み、識別がなされる点に留意する必要がある。
1.4 ゲノムデータベースと血縁情報の取得
ゲノムデータの収集には、血縁情報も強く関連するため、個人ゲノムと同時に収集される事が多く行われている。家系の誰か一人が、匿名化されたデータベースから再識別されたば場合には、残りのメンバーの再識別が容易である。特に、SNSでは血縁関係が公開されているケースが存在する他、家系図のSNSサービスも登場している。米国におけるGeniや日本においても、血縁関係者を基盤にしたSNSがあり、これらの情報とゲノムデータベースを照合された場合に、再識別が可能である。
1.5 統計的推定による属性推定
血縁関係にないゲノムと形質の依存性を分析するゲノムワイド相関分析(GWAS)では、特定の疾患遺伝子を統計的に同定する。これによって、あるゲノムをもつ個人がある疾患に羅患するリスクについて評価をする事が可能である。
GWASを目的とした、ある対象疾患をケースとした対立遺伝子の頻度が公開されている とき、ある個人がどちらのグループ(疾患に羅患しているか/していないか)を統計的に推測する事が可能であるとの報告が2008年になされた。この報告をうけて、NIHでは公開情報としていたGWASに関する頻度表を非公開とした。頻度表は基本統計量において学術論文でも示されることから、この取扱についてリスクが指摘されている。
1.6 連鎖不平衡を用いた推定
センシティビティの低いSNP情報を使って、センシティビティの高いSNP情報を推定する方法が提案されている。これは、Marchiniら(2010)[2]による提案で、完全な遺伝型の情報を持つReference Populationの情報と連鎖不平衡から、欠損値を持つ遺伝情報について、その欠損値を隠れマルコフモデルなどの方法によって補完する方法を示している。
2.アイデンティティとブロックチェーン
本章ではアイデンティティ管理の新しい技術としてブロックチェーン技術が現れていることを踏まえ、IDを持たない個人に対してアイデンティティ付与の新しい動向について記述する。
2.1 BitnationおよびBitnation Refugee Emergency Response (BRER)
2.1.1 Bitnation
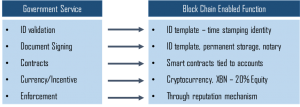
Bitnationはこれまでの伝統的な国家の枠組みに対する代替的な枠組みとして、非中央集権的でボランタリーで、ボーダレスなバーチャルな国家を作るプロジェクトとして2014に開始された。当初はBitcoin Blockchain上でIDを管理およびそれに付帯するサービスを提供していたが、現在はEthereumベースで構築されている。
Bitnationはバーチャルな国家として既存の国家よりもより良く、また安く様々なサービスを提供している。主要なサービスは以下のものである。
図:Bitnaitonが提供するサービスおよびテクノロジー
Bitnationが提供する主要なサービスにIDテンプレートの提供がある。Bitnationが提供したブロックチェーンに自らのアイデンティティを登録することで、IDが発行される。

現在、BitnaionはPangeaというアプリケーションを開発し、トークンセールを実施している[3]。ユーザーはまず、PangeaのAppをダウンロードし、Pangeaの市民となる。その後、Pangea内に作られた仮想的な国家の国民として登録する事が可能である。Pangeaは仮想的な国家を立ち上げるための新しいプラットフォームとして解する事が可能である。
2.1.2 e-Estonia:エストニアとの連携
エストニアでは、政府業務の電子化を世界に先駆けて実施をしてきた。エストニアは世界で初めて外国人の電子居住者を認める政策を2014年に開始している。これはどこの国に居住していても、また国籍に関係なくエストニアのe-residencyに登録すればエストニアでの(エストニア法に基づく)会社設立、金融取引等の行政サービスの利用が可能になる。
エストニアは2015年にBitnationと提携し、e-ResidencyをBitnationの支援を得て、ブロックチェーンで管理することにしている。
2.1.3 Bitnation Refugee Emergency Response (BRER)
2015年から開始された、難民に対する緊急的IDを発行するプロジェクトである。シリアを中心とした難民の増加にともなって、IDがない人々が多く発生する事になった。そこでBitnationはBRERを開始した。
BRERはブロックチェーンベースのIDを難民に付与し、その存在証明(Proof of Existence)をするものである。これは公的なIDがなくとも、BitnationのIDを付与され、個人の存在証明および家族関係を示す。個人の身元を明らかにすることに加えて、特に他国に移住した親や子供等の家族と再開するためにより有力な手助けとなりうることを企図している。
また、BitnationはVISAと提携を行っているため、BRERでIDを作成した難民に対して、他社から寄付を募り、デビットカードで支払いを行う事ができるようなプログラムも提供している。
2.2 ID2020および国際機関におけるブロックチェーンとバイオメトリクス認証
2.2.1 ID2020の概要
現在、世界には1.1Bilionの公的なIDを持たない人々が存在する。国連では2030年までにすべての人に出生証明を含む法的なアイデンティティを付与することを、目標に[4]掲げている。
ID2020は官民共同のプログラムとして、すべての人にデジタルアイデンティティを付与することを目的にアクセンチュア、マイクロソフト、UNHCR、GAVIなどによって設立された。ID2020は以下の特性をもったデジタルアイデンティティの開発を目指している。
1.個人の特定:ユニークで個人を限定する
2,永続性:出生から死亡までの範囲をカバー
3.プライベート性;データの利用について本人のみが許可をする
4.ポータブル;どこでも用いる事が可能
2.2.2 ID2020におけるBiometrics認証の導入
ID2020のプロトタイプは2017年に公開された。ID2020はEnterprise Ethereumを用いて開発され、MicrosoftのAzureクラウドコンピューティングプラットフォーム上で実行される。このプラットフォームはバイオメトリクス認証を導入している点である。指紋や交際のバイオメトリクス認証を付与することで信頼性を担保するとともに、他の個人情報を登録することなく個人を識別し、デジタルアイデンティティの付与を行う事が可能になった。
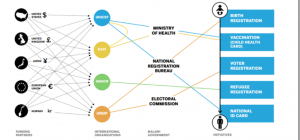
2.2.3 UNHCR – Biometric Identity Management System[5]
国連の難民に関する問題を取り扱うUNHCRは、2015年に難民管理の方法として- Biometric Identity Management System(BIMS)を導入した。このシステムはアクセンチュアによって開発され、虹彩および指紋を登録することで、難民の身元確認方法を提供する。このシステムは各国のUNHCR事務所で登録したアイデンティティ情報をジュネーブに保管するデータベースに接続するシステムである。すでにタイ、南スーダン、チャドの難民に適用されている。
前述のID2020におけるバイオメトリクス認証はこのBIMSとの連携を将来的に視野にいれている。
3.ゲノム解析とゲノム産業について
本章では、究極の個人情報であるゲノム情報を得るためのゲノム解析サービスや個人ゲノム情報を活用する様々なゲノム産業の動向について記述する。
3.1ではゲノム解析技術の変化、3.2ではゲノム解析の低コスト化、3.3~3.5では、日本・米国・中国のゲノム解析サービスの動向、3.6では医療以外の分野にゲノム情報を用いたサービスとスタートアップ企業、3.7では、「個人」がゲノム情報活用の権限を持つ次世代型のゲノム活用サービスについて示す。
3.1 ゲノム解析技術
2003年に、ヒトゲノムの30億塩基対の配列が、国際プロジェクトにより解読された。このときは、ヒトゲノムをランダムに断片化し、その断片を大腸菌に入れて増やしてから、シーケンサーという自動化機械で塩基配列の読み取りをしていた。読み取り方法は、DNA複製反応で塩基が次々に取り込まれることを利用し、A、T、G、Cを異なる色の蛍光色素で見分けていた。こうして読み取られたDNA断片の塩基配列を比べて、どこが重なるかを調べ、パズルのようにつなぎ合わせてゲノム全体の塩基配列を決定していた。このプロジェクトには、日本を含め世界各国の多くの研究者が参加し、長い年月を要した。
しかし、2000年代の後半になって、新たなしくみのシーケンサーが登場した。塩基配列の読み取り速度は一気に向上し、現在では、ヒトゲノムの塩基配列を数日で読み取れるほどになっており、これらのシーケンサーを「次世代シーケンサー」と呼んでいる。次世代シーケンサーの活用により、多数のゲノムを解読することが可能になった。次世代シーケンサーは、断片化したDNAをそのまま装置に導入し、ビーズやガラス基板上にDNAの断片を固定し、塩基配列の読み取りに進み、多数のDNA断片の塩基配列を一度に読み取ることができるようになった。ゲノム解析技術の模式図、進歩を以下に示す。
図:シーケンサーによる塩基配列決定法[6]
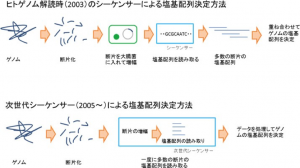
表:シークエンス技術の発展に伴う作業工程の変化と解読できる塩基数[7]
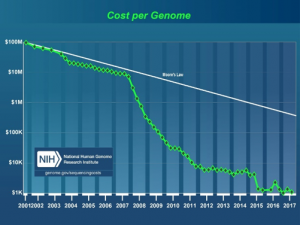
3.2 ゲノム解析コスト
上述のように近年における、生物の持つ遺伝子情報であるゲノムを解析する技術革新は著しい。技術開発による、コストへの影響を図に示す。かつて3000億円以上を要したとされる1人当たりの全ゲノム解析コストは、ヒトゲノムプロジェクト終了(2003年)から数年の間はムーアの法則に沿うレベルで進んでいた。しかい、次世代シーケンサーが登場した2007年以降、急ピッチでコストは下がり、現在では消費者が少し背伸びすれば買える価格で、サービスを提供できるまで下がった。
図:ゲノム解析コストの推移[8]
遺伝子解析技術の低価格化を背景に、遺伝子検査サービスなどのゲノム産業が世界的に活発になってきている。特に近年は、消費者向け(Direct to Consumer:DTC)の遺伝子検査サービスが広がっている。
3.3 国内のゲノム解析サービスの動向
3.3.1 国内DTC企業の動向
日本国内では2014年1月に東京大学発ベンチャーのジーンクエスト(2017年ユーグレナが買収)が日本初の消費者向け(Direct to Consumer:DTC)の大規模遺伝子解析サービスを開始し、その後、相次いで大手IT企業が参入した。
DTCとは、下記に該当するサービスである。[9]
○ 消費者自ら検体を採取。消費者に直接検査結果が返される。
○ 統計データに基づき、疾患の罹患リスクや体質等を示すもの。
○ 疾患リスクは、生活習慣病等の多因子疾患のみ対象(単一遺伝子疾患は対象外)
○ 疾病の診断や治療・投薬の方針決定を目的とした医療分野の検査とは異なり、利用
者に気付きを与え、利用者自らの行動変容を促すサービス
図:DTC流れ
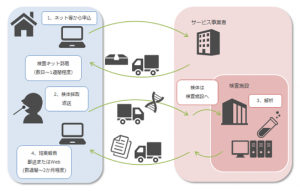
これらのサービスは公的保険外で行われている。参入した企業はDTCサービスの核となるのは、一塩基多型(SNP)解析の結果から体質や疾患易罹患性の評価結果を導き出すためのアルゴリズムである。論文などを参照し、体質に影響する因子や疾患のリスク因子として報告されているSNPの中から解析対象の選別を行う。報告されているオッズ比やSNPの頻度などから、「骨密度が低くなりやすい」といった定性的な評価結果や、「骨粗鬆症に日本人の平均より1.2倍なりやすい」といった定量的な評価結果を導き出す。
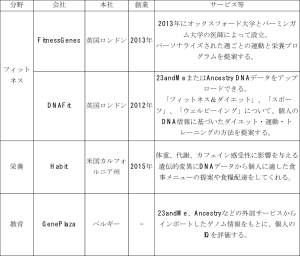
こうした独自のアルゴリズムを開発し、サービスを提供している主な国内企業、代表的なサービス等を以下に示す。
表:国内DTC企業
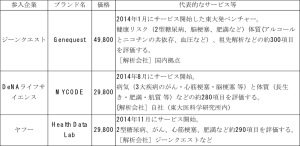
*価格やサービスは各社ホームページを踏まえ作成。
初期は、国内で各社が開始した遺伝子解析サービスは、「顧客からDNAの提供を受けて、解析し、その結果を返す」というシンプルであり、DNA解析データはサービス提供会社が保管し、新たな知見に応じてレポートの更新を行っていた。近年はユーグレナがジーンクエストを完全子会社化したように、運動や食生活などについて、ユーザーに適切なアドバイスをする過程で、自社商品の購入に繋げることや、顧客の同意を得たうえで、解析データを研究機関へ研究用に提供し、そこから得られた新たな知見(遺伝子と病気のなりやすさの関係)をサービスに活かす動きが加速している。DeNAライフサイエンスはMYCODEを利用した顧客から、遺伝情報などを研究活動に利用する旨の同意を約8割から得ており、今後、病気や体質、生活習慣と遺伝子の関係を解明する研究へ任意で参加してもらう計画を立てている。国内DTC企業の最近の主な動きは以下のものである。
表:国内DTC企業の最近の主な動き

*最近の主な動きを調査し、作成。
3.3.2 バイオバンクについて
企業による遺伝子検査サービス以外にも、提供されたヒトの細胞、遺伝子、組織等について、研究用資源として品質管理を実施して、不特定多数の医学研究に利用するバイオバンクが整備されてきている。
ゲノム情報を疾患の予防に活用するという観点からは、そのデータベースづくりともいえる「ゲノム コホート研究」への取り組みが、日本を含め世界各国で計画あるいは開始されている。「コホート研究」 とは、疾患と環境との関係について、特定の地域や集団に属する人々を長期にわたって追跡調査する、 疫学における研究手法の一種である。「ゲノムコホート研究」は、健常人の集団を対象に、様々な医学的 情報や環境・生活習慣に関する情報とあわせてゲノムデータも収集し、対象者が発症した疾患と治療、 その治療への反応、といった事項との関連について長期にわたり解析しようとするものである
がんや生活習慣病を含む多くの疾患は、複数の遺伝子による「遺伝要因」と生活習慣等の「環境要因」 との両方が影響して発症する多因子疾患であることが判明してきている。
図:遺伝要因と環境要因の関係[10]
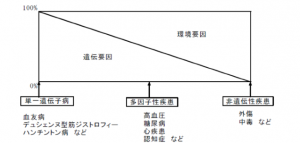
遺伝子・環境・疾患発症の関 連が明らかになれば、個人差(遺伝子の差)に応じた生活習慣等の改善によって疾患の予防・抑制が可 能になるばかりでなく、将来的には、その膨大なゲノムデータが創薬や個別化医療の基盤となることも期待される。
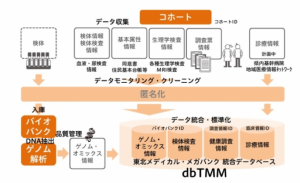
日本では、国内バイオバンクに「東北メディカル・メガバンク機構」(ToMMO)がある。ToMMoは東日本大震災で未曾有の被害を受けた被災地住民の健康不安の解消に貢献するとともに、個別化予防等の東北発次世代医療の実現を目指し、2012年に設立された。この機構では、岩手、宮城両県の約15万人分の血液や尿を集め、遺伝子を解析している。提供者の健康状態を追跡調査して照合すると、病気と関連する遺伝子情報が紐づけされていく。いわゆる「ゲノムコホート研究」としては日本最大規模を誇る。東北メディカル・メガバンク計画が行う大規模ゲノムコホート調査由来の健康調査情報及び解析情報を格納したデータベース、統合データベースdbTMMを構築しており、統合データベースdbTMMには、基本属性情報(性別・年齢等)、検体検査情報、ゲノム・オミックス情報、調査票情報などが格納されている。所定の登録・審査の手続きを経て、全国の研究者の皆さまにご利用いただくことが可能である。さらに、統合データベースdbTMMで閲覧可能な情報をもとに試料・情報分譲を行い、研究利用することもできる。
図:統合データベースdbTMM
3.4 米国のゲノム解析サービスの動向
3.4.1 米国DTC企業の動向
米国のDTCの主要業者のユーザー数は昨年から急増し、全体で1200万人以上に達した。[11]
図:米国のゲノム解析サービスユーザー数の推移
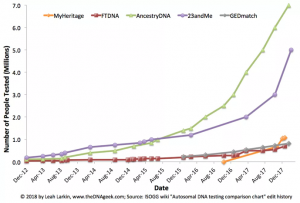
つまり米国(総人口が約3億人)では、既に25人に一人が遺伝子検査サービスを利用していることになる。主な米国のDTC企業、サービス等を以下に示す。
表:米国DTC企業
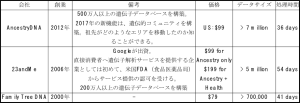
*価格やサービスは各社ホームページを踏まえ記載。
米国でDTCの草分けで、Googleも出資している「23andMe」が設立されたのは2006年のことである。当初こそ、利用者数を伸ばしたが、遺伝子検査サービスの信頼性(精度)に対する、根本的な疑問が投げかけられた。こうした事態を受け、この分野をリードしてきた23andMeが、2013年11月に米連邦政府の規制当局であるFDA(食品医薬品局)からサービスの差し止め命令を受け、「病気へのかかり易さ」など医療・健康関連の検査サービスは停止に追い込まれた。一方で「先祖探し」など、ユーザーの生命や健康に差しさわりのない、エンターテイメント的なサービスは継続して提供することが許可された。その後99%の診断精度を証明し、2017年4月に、23andMeは医療・健康関連でも「パーキンソン病」や「アルツハイマー病」、 「遺伝性血栓症」など10種類の病気に限って、これらに関する遺伝子検査サービスをユーザーに提供することが許可された。
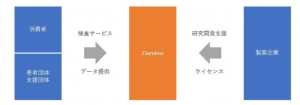
23andMeのビジネスモデルは遺伝⼦解析サービスとしてのB2Cモデルと、製薬企業に対する研究開発⽀援を⾏うB2Bモデルの側⾯がある。まず、消費者向けサービスは2007年から提供されるようになった。FDAからの承認が下りるまでは健康診断を⾏っていなかったが、遺伝⼦解析による健康診断サービスとして成⻑を遂げている。B2Cサービスの成功は、23andMeにとって、収益を上げる以上に⼤きな意味があった。200万⼈以上の遺伝⼦データベースを構築した同社は、そのデータを使って、医薬品開発の⽀援を⾏えるようになったからだ。効果の⾼い薬を開発できれば、その収益は莫⼤なものになるため、製薬会社との協業は23andMeに⼤きな収益をもたらす可能性がある。遺伝⼦情報を提供した消費者のうち、80%は製薬会社との共同研究にデータを利⽤することを許諾しているという。難病の治療⽅法を確⽴する社会的な意義を考えれば、匿名化された状態でデータを転⽤されるのも消費者に受け⼊れられやすい。B2Cで健康診断を⾏い、B2Bで活⽤する基礎データを収集するというビジネスモデルは、データを中⼼に事業が展開される遺伝⼦解析業界では、極めて強⼒だといえる。
図:23andMe ビジネスモデル
そして2018年3月、23andMeは乳がんの主な原因とされる「BRCA1、2」に関する遺伝子検査についてもFDAから許可された。米国の消費者は23andMe、ひいては同社に代表されるDTCに対して、ある程度の信頼感を持ち始めた。これが(前述の料金低下や大量の広告費を投入し始めたことなどとあいまって)最近のDTCの利用者増加に結び付いている。
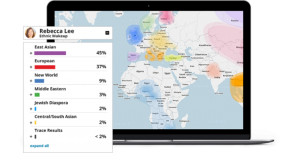
またヘルスケア以外にも、先祖探しを目的に受けている。このサービスは、伝統的に移民国家、他民族国家である米国では「自分の先祖が地球上のどこから来て、どんな民族であったか」に関心を持つ人が多いため利用者が多い。
図:ユーザーに提供する先祖探しデータ
3.4.2 医療専門家を通したゲノム解析企業の動向
DTCとは異なり、病院で医療関係者を通したゲノム解析も行われている。これらの解析の目的は、がん治療など医療行為に直結するためとなる。2013年には、ユタ州のMyriad Geneticsのゲノム結果を受けて、米国女優のアンジェリーナ・ジョリーが発症前に、乳がん予防のための乳房切除術を受けたことが報じられ注目を集めた。彼女の母の家系がこの変異を持っており、母を含めた3人の近親者が遺伝性の乳がんと卵巣がんで早世していることや、「BRCA1」という単一の遺伝子の影響によって、将来の乳がんや卵巣がんの発症リスクが極めて高いことが判明、将来的に乳がんを発症する確率が87%と見積もられた結果の判断であった。2017年にコニカミノルタに買収されたカルフォニア州のAmbry Geneticsは2018年3月、DTC企業の解析結果には40%の誤りがあると発表した。DTCへの懸念を示すなど懐疑的立場を示しており、今後の動向が注目されている。[12]米国での医療専門家を通した遺伝子検査企業を以下に示す。
表:米国の医療専門家を通した遺伝子検査企業

3.5 中国のゲノム解析サービスの動向
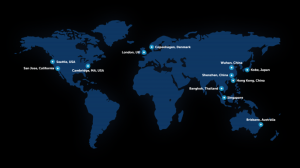
中国においてもゲノムサービスは増加している。その中でも、BGIは世界最大規模のDNAシークエンシングセンターで遺伝子配列解明に寄与してきた。1999 年9 月9 日、中国・北京で設立された。2007 年に本社を深センに移転し、中国以外でも活動を行っている。
図:BGI拠点[13]
7年前、当時世界最速のシークエンサーであった「イルミナHiSeq200」を128台購入した。これによりBGIはイルミナの最大顧客となった。2014年までに、BGIは世界のゲノムデータの少なくとも4分の1を生み出すまでになっており、これは地球上のどの研究機関よりも多い量である。
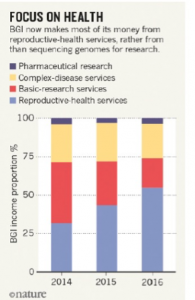
しかし、ここ数年はマシンの型落ちにより、イルミナや中国の競合相手であるNovogeneが送り出す、より新しく、速く、安く、強力なシークエンサーの台頭を許している。そこで2013年、BGIはイルミナの競合となる米国企業コンプリート・ゲノミクスを買収し、自分たちでシークエンサー開発を行い、15年後半にシークエンサー「BGISEQ-500」を発表した。同社によると、ヒトゲノム全体の解析を600ドルで完了できるもので、この価格はイルミナの同等製品と比べて40パーセントも安い。また、近年は、リプロダクティブ・ヘルスの比率が増えている。[14]
図:BGIのマーケット(2014~2016年)
2016年に、中国の国家食品薬品監督管理局(CFDA)はBGI製シークエンサーの医療器具申請を承認し、臨床遺伝子検査での使用を許可した。2017年には深セン証券取引所でIPOを行い、今回の資金調達で、高精度医療サービスの拡充、ゲノム編集研究センターの建設、クラウドサービスシステムの開発を行うと見られている。
3.6 医療分野以外のゲノム情報を用いたサービス
これまでゲノム情報の解析サービスや医療分野(一部祖先探し)について述べてきた。最近では、医療分野以外でも、フィットネスなどのヘルスケア分野での活用はすでに世界中で広がっている他、「ニュートリゲノミクス(栄養とゲノム)」や「エデュケーショナルゲノミクス(教育とゲノム)」等の研究分野も進展しており、単にゲノム情報を医療に活用するのではなく、ゲノム情報を利用した分野は今後さらに広がる可能性がある。世界では、ゲノム情報を活用した様々なスタートアップ企業が創業している。各スタートアップについて以下に示す。
表:ゲノム情報を用いたサービスと企業
フィットネス関連では、英国のスタートアップ企業「Fitness Genes」や「DNAFit」がある。Fitness Genesは2013年に創業し、家庭のDNA検査キットの結果に基づいて個人向けのパーソナライズされたフィットネスおよび栄養計画を作成してくれる。DNAFitは、2012年に創業し、オリンピック選手が活用するほど浸透してきている。23andMeまたはAncestry ゲノム情報を活用することができ、「フィットネス&ダイエット」、「スポーツ」、「ウェルビーイング」など、個人のDNA情報に基づいたダイエット・運動・トレーニングの方法を提案してくれる。
ニュートリゲノミクス関連では、2015年米国のスタートアップ企業「Habit」が創業している。ゲノム情報を活用することによって、体重、代謝、カフェイン感受性に影響を与える遺伝的変異について分析し、個人に適した食事メニューの提案や食糧の配達する。
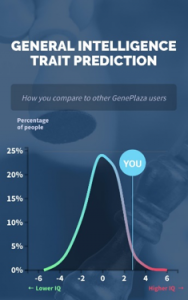
エデュケーショナルゲノミクス関連では、「GenePlaza」が23andMe、Ancestryなどの外部サービスからインポートしたゲノム情報をもとに、個人のIQを示すサービスを行っている。[15]
図:GenePlaza ユーザーのIQ
3.7 次世代型のゲノム活用サービス
3.7.1
「個人」がゲノム情報を活用するゲノム統合型サービス(AWAKENS)
これまで述べてきたように、世界的にゲノム情報を持つ人々は激増している。また単にゲノム情報を入手し、医療分野にのみ活用するのでなく、ゲノム情報を様々なサービスに活用するスタートアップ企業が生まれており、ゲノム情報の価値は多様になってきている。一方、ゲノム情報を活用するためには、質の高いゲノム解釈情報のデータベースやオペレーションの構築、究極の個人情報であるゲノム情報のセキュリティにかかる投資が数千万円〜数億円に上り、参入は容易ではなく、ゲノム情報を使用したサービスの広がりの障害になっている。
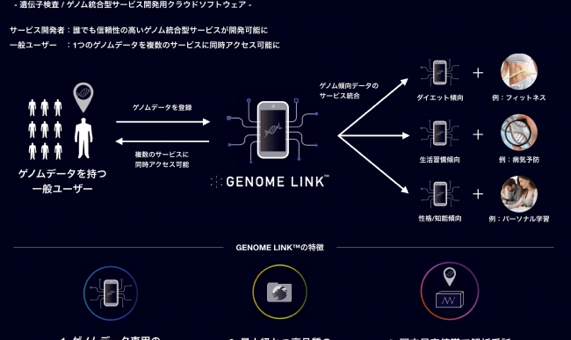
その状況を打破するため、2017年1月に創業した「AWAKENS」は、ゲノム統合型サービスのプラットフォーム構築を進めている。人々がまず自分の全ゲノムを手頃な値段で取得した上で、状況に応じて知りたい情報をそのつど引き出し、それによってサービスという恩恵にアクセスできる世界を目指す。
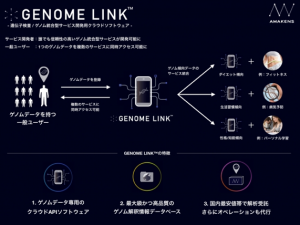
ユーザーのゲノムデータの取得、専用の高セキュリティ環境でのデータ管理、国内外最高レベルのデータベースにもとづく信頼性の高いゲノム解釈情報の連携までを、クライアント側の開発者によるコーディングだけで実装できるようにしたAPIソフトウェアGENOME LINKを開発した。このソフトウェアにより、これまで高い初期投資とセキュリティリスク等の懸念からゲノム分野に参入ができなかった企業でも、質の高いゲノム統合型サービスを提供できるようになり、当たり前のようにゲノム情報を活用することができるようになる。
現在は個別のゲノム検査サービス毎に解析をしているが、一度解析したデータをユーザーがオーナーシップを持ち、自由に活用できるようにすることで、ゲノムがもつデータの価値と、コスト構造を一気に変える可能性が出る。
図:ゲノム統合型サービスを開発できるAPIソフトウェア「GENOME LINK™」
このようなゲノム統合型サービスは、既存の消費者向け(DTC)遺伝子検査サービスと異なり、ゲノム情報の囲い込みなどは意図せず、個人が当然のように自分のゲノム情報を持ち歩くような時代が来ることを想定している。ユーザー自身は1回だけ全ゲノム解析を行い、そのデータを決済システム導入に「Paypal」(金銭の授受をPayPalが仲介するため、取引先にクレジットカード番号や口座番号を知らせる必要がない)を使うように活用し、自分のゲノム情報に応じた製品やサービスの提供を受けられる。DTC企業がデータを所有するこれまでのシステムと異なり、個人がゲノム情報の権限を持ち、管理できるシステムとなる。
3.7.2
「個人」がブロックチェーンでゲノム情報を売買できるサービス(Nebula Genomics)
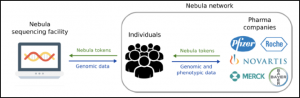
Awakensのように、ゲノム解析企業ではなく、個人が全ゲノム情報を所有し、活用できるスタートアップ企業として、「Nebula Genomics」があげられる。莫大な個人データを所有していたFacebookのデータ流出の歯止めとして、ブロックチェーンが注目されているように、米スタートアップ「Nebula Genomics」は、ブロックチェーン技術をベースに、全ゲノムデータの所有権を個人が持ち、個人が遺伝子の情報を売買できることを目指している。Nebula Genomicsは、ハーバード大学の遺伝学者ジョージ・チャーチ教授が創業した。現在、ブロックチェーン技術で遺伝子データを共有・売買・分析できるプラットフォームの構築に乗り出している。[16]
Nebula Genomicsのネットワークを活用することで、個人が、自分の遺伝子情報を研究目的で使用する製薬会社・研究機関などに売ったり、寄付できる。一方、製薬会社・研究機関などは、データの所有者である個人にコストを支払うことになる。 引き替えに支払われるのは、Nebula社独自の仮想通貨であるトークンを予定している。
遺伝子およびゲノム研究・産業が活性化するためには、より多くの量のビッグデータが必要となる。しかし、それぞれのデータが散在しているうえ非標準化されており、個人情報保護との絡みもある。そこで、彼らはブロックチェーン技術に注目した。
現段階では、Facebookがプラットフォームとして、個人情報を所有しているように、データの所有者と購入者との間には、23andMeやHelixといったゲノム解析サービス企業が存在している。
図:Nebula Genomicsと他ゲノム企業との比較

しかし、所有者がブロックチェーンベースのネットワークに加入すれば、購入者と直接つながることができる。データの所有者である個人は、自分のデータに第三者がアクセスすることを防ぎつつ、トークンを使って自分の遺伝子分析サービスを受けることもできる。またブロックチェーンの技術を使用すれば、研究者や製薬会社が契約に違反することも把握でき、利用者が自身の究極の個人情報の管理をすることができる。
図:既存DTCのビジネスモデル
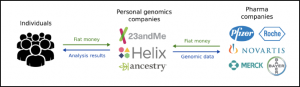
図:Nebula Genomicsのビジネスモデル
[1] 佐久間淳. “ゲノムとプライバシー.” 電子情報通信学会 基礎・境界ソサイエティ Fundamentals Review 7.4 (2014): 348-364.
[2] Marchini, Jonathan, and Bryan Howie. “Genotype imputation for genome-wide association studies.” Nature Reviews Genetics11.7 (2010): 499.
[3] PangeaのWhitePaper:
https://github.com/Bit-Nation/Pangea-Docs/raw/master/BITNATION%20Pangea%20Whitepaper%202018.pdf
[4] 国連 Sustainable development goals:Goal 16 Promote just, peaceful and inclusive,9 By 2030, provide legal identity for all, including birth registrations. http://www.un.org/sustainabledevelopment/peace-justice/
[5] http://www.unhcr.org/protection/basic/550c304c9/biometric-identity-management-system.html
[6] 文部科学省次世代がん研究シーズ戦略的育成プログラム HP
[7] ゲノム解析技術の進展と課題 社会技術研究論文集 Vol.11,138-141,April 2014
[8] National Human Genome Research Institute’DNA Sequencing Costs: Data’
https://www.genome.gov/27541954/dna-sequencing-costs-data
[9] 厚生労働省 ゲノム医療等実用化推進TF資料
http://www.mhlw.go.jp/file/05-Shingikai-10601000-Daijinkanboukouseikagakuka-Kouseikagakuka/160127_s4.pdf
[10]– 金融庁 遺伝子検査と保険 https://www.fsa.go.jp/frtc/nenpou/2005/06.pdf
[11] The International Society of Genetic Genealogy ‘Autosomal DNA testing comparison chart’ http://thednageek.com/dna-tests/
[12] False-positive results released by direct-to-consumer genetic tests highlight the importance of clinical confirmation testing for appropriate patient care
https://www.nature.com/articles/gim201838
[13]BGI
HPhttps://www.bgi.com/jp/company/bgi%E3%81%AB%E3%81%A4%E3%81%84%E3%
[14] ‘China’s genomics giant to make stock-market debut’
https://www.nature.com/news/china-s-genomics-giant-to-make-stock-market-debut-1.22171
[15] MIT Technology Review
‘DNA tests for IQ are coming, but it might not be smart to take one’
[16] Nebula Genomicのwhitepaper
https://www.nebulagenomics.io/assets/documents/NEBULA_whitepaper_v4.52.pdf
Copyright © 合同会社SARR All rights reserved.